Java
[Java] 우선순위 큐의 우선순위는 어떻게 지정할 수 있는가
- -
728x90
다양한 알고리즘을 접하며 우선순위 큐를 종종 사용하곤 한다. 항상 정렬된 상태를 유지하고는 있는데 이게 어떠한 방식으로 돌아가는 지 파악하기 위해 이 글을 작성한다. 우선순위 큐와 관련된 힙에 대한 내용도 담아보자.
🟢우선순위 큐 (PriorityQueue)
큐(Queue)는 먼저 들어오는 데이터가 먼저 나가는 FIFO(First In First Out) 형식의 자료구조이다. 우선순위 큐(Priority Queue)는 먼저 들어오는 데이터가 아니라, 우선순위가 높은 데이터가 먼저 나가는 형태의 자료구조이다.
우선순위 큐는 일반적으로 힙(Heap)을 이용하여 구현한다
💡 힙(Heap)이란 ?
힙(Heap)은 우선순위 큐를 위해 고안된 완전이진트리 형태의 자료구조이다. 여러 개의 값 중 최댓값 또는 최솟값을 찾아내는 연산이 빠르다.
힙(Heap) 의 특징
- 완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조이다.
- 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조이다.
- 힙은 일종의 반정렬 상태(느슨한 정렬 상태) 를 유지한다.
- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다는 정도
- 간단히 말하면 부모 노드의 키 값이 자식 노드의 키 값보다 항상 큰(작은) 이진 트리를 말한다.
- 힙 트리에서는 중복된 값을 허용한다. (이진 탐색 트리에서는 중복된 값을 허용하지 않는다.)
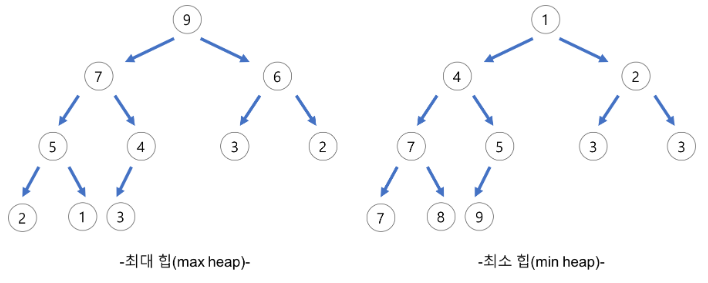
힙(heap)의 종류
🔻최대 힙(max heap)
부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
key(부모 노드) >= key(자식 노드)
🔻최소 힙(min heap)
부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
key(부모 노드) <= key(자식 노드)
✅ 우선순위 큐의 우선순위
Java 의 `PriorityQueue' 는 내부적으로 원소들을 우선순위에 따라 정렬하는 큐다. 이 큐에서의 정렬 기준은 두 가지 주요 방법으로 정해질 수 있다. 자연 순서를 사용하거나, 명시적으로 정의된 `Comparator`를 사용하는 방법이다.
1. 자연순서 (Natural Ordering)
큐의 원소가 `Comparable` 인터페이스를 구현한 클래스의 인스턴스인 경우, 이 인터페이스의 `compareTo` 메서드에 정의된 자연 순서가 우선순위 큐의 정렬 기준이 된다. 이 경우, 원소들은 `compareTo` 메서드에 의해 비교되어 우선순위 큐에 자동으로 정렬된다.
// Integer는 Comparable을 구현함
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(10);
pq.add(5);
pq.add(20);
// 자연 순서대로 출력될 것임
while (!pq.isEmpty()) {
// 5, 10, 20 순서로 출력
System.out.println(pq.poll());
}
사실 이 부분이 제일 궁금한 사항이였다. PriorityQueue<Integer> pq 처럼 선언만 해주었는데 자동으로 정렬된다니 .. 그 이유는 아래의 Integer.java 를 확인해보면 Comparable 인터페이스를 구현하고 있음을 확인할 수 있다.


2-1. Comparator 를 사용한 정렬
사용자가 `Comparator` 인터페이스를 구현하여 정렬 기준을 명시적으로 제공할 수 있다. 이 방법은 `PriorityQueue`의 생성자에 `Comparator` 객체를 전달함으로써 사용된다. 이 `Comparator`는 큐에 추가되는 각 원소를 비교하는 데 사용되며, 람다 표현식을 통해 간결하게 정의할 수 있다.
PriorityQueue<int[]> pq = new PriorityQueue<>(Comparator.comparingInt(a -> a[0]));
pq.add(new int[]{3, 2});
pq.add(new int[]{1, 5});
pq.add(new int[]{2, 8});
// 첫 번째 원소를 기준으로 정렬된 순서대로 출력될 것임
while (!pq.isEmpty()) {
int[] arr = pq.poll();
// [1, 5], [2, 8], [3, 2] 순서로 출력
System.out.println(Arrays.toString(arr));
}
여기서 Comparator.comparingInt(a -> a[0])는 배열의 첫 번째 원소를 정렬 기준으로 사용하도록 설정한다.
2-2. 클래스를 사용한 `Comparator` 구현
더 복잡한 비교 로직이 필요한 경우, `Comparator` 인터페이스를 구현하는 별도의 클래스를 만들 수 있다. 이 클래스에서는 `compare` 메서드를 오버라이드하여 정렬 로직을 구현한다.
class ArrayComparator implements Comparator<int[]> {
@Override
public int compare(int[] a, int[] b) {
return Integer.compare(a[0], b[0]);
}
}
..
..
PriorityQueue<int[]> pq = new PriorityQueue<>(new ArrayComparator());
pq.add(new int[]{3, 2});
pq.add(new int[]{1, 5});
pq.add(new int[]{2, 8});
while (!pq.isEmpty()) {
int[] arr = pq.poll();
// [1, 5], [2, 8], [3, 2] 순서로 출력
System.out.println(Arrays.toString(arr));
}
아래의 방법은 알고리즘을 풀이할 때, 제일 많이 사용하는 방법이라서 참고용으로!
static class Node implements Comparable<Node> {
int[] node;
Node(int[] N) {
this.node = N;
}
@Override
public int compareTo(Node o) {
return this.node[0] - o.node[0];
}
public String toString() {
return this.node[0] + ":" + this.node[1];
}
}
..
..
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(new int[]{3, 2}));
pq.add(new Node(new int[]{1, 5}));
pq.add(new Node(new int[]{2, 8}));
while (!pq.isEmpty()) {
Node arr = pq.poll();
// [1, 5], [2, 8], [3, 2] 순서로 출력
System.out.println(arr.toString());
}728x90
'Java' 카테고리의 다른 글
| [Spring] 성능 테스트 ? Locust로! with Docker (0) | 2024.05.23 |
|---|---|
| [Spring] Spring Boot 에서 멀티 모듈 구현 (0) | 2024.05.22 |
| [Java] 정적(static) 이란 무엇인가 (0) | 2024.04.29 |
| [Java] 제네릭(Generic) 은 무엇인가 (0) | 2024.04.26 |
| [Java] Java 에서 인터페이스는 왜 쓰는 것일까 (0) | 2024.04.25 |
Contents
소중한 공감 감사합니다